




基于python的移动网络优化自动化与数据分析探索
云成龙
中国联合网络通信有限公司巴彦淖尔市分公司 015000
摘 要:由于移动网络复杂度的提升及网络承载数据的激增,网络优化工作人员以传统方式对网络进行优化及对网络数据进行分析就显得捉襟见肘,为能够对网络进行更好的优化及对网络数据进行深度分析,本文就基于python对移动网络优化过程中的详细告警监控分析及网络数据深度挖掘分析进行了探索,设计了程序算法完成了上述工作。
关键词:Python,网络爬虫,移动网络优化自动化,移动网络数据挖掘分析
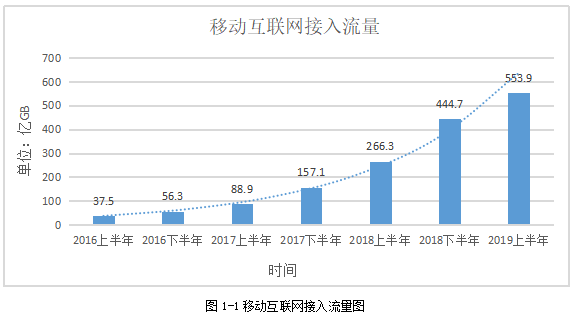
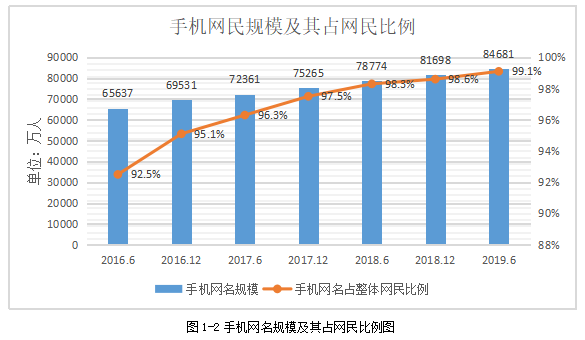
随着移动网络的发展壮大,地市网络优化部门逐渐面临一个重大的难题,那就是维护的网络越来越复杂,尤其随着5G的到来,就形成了2G/3G/4G/5G同时共存的一个复杂而庞大的网络,每个网络一定程度上存在独立性,有自己的数据平台,这就导致有多个平台的网络数据需要人工下载并整理分析,耗费了大量的人力资源,公司要承担较大的人力成本,整体效率低下;同时多个平台产生的数据量较大,从用户使用移动手持终端侧流量可印证,据第44次中国互联网网络发展状况统计调查报告称[1],移动互联网接入流量连年快速增高,手机用户数也平稳增长,从统计可知:2019年上半年是2016年上半年的14.7倍,增长约516.4亿GB。手机网络网民人数在2019年也达到了8.4亿人。如此多的流量及用户产生的上网信令等其他数据同样巨大,普通的数据处理分析软件如excel等无法满足数据分析要求,导致网络问题等无法快速发现,数据资源挖掘力度不足,巨大潜力无法释放,但与此同时用户感知及要求变的越来越高,形成网络与用户感知间的矛盾。
研究目的一方面是为减轻工作人员重复性劳动,提升工作人员工作效率,节省公司人工成本,另一方面对移动网络正常运行及影响用户感知的告警,做到及时发现,自动提出解决措施,及时处理故障,来提高用户使用网络的感知,提升用户对网络的满意度。本文特设计了具有代表性并有可延展性的基于python的移动网络优化告警实时监控程序,同时为探索地市住宅小区的网络覆盖情况、用户感知及住宅小区内用户市场占有率等情况,本文基于python对地市住宅小区进行了数据挖掘探索,为网络未来建设及市场未来发展提供决策参考。
基于python的移动网络优化与数据分析挖掘对移动网络优化自动化及智能化发展有助推剂的作用,为国家数字化经济转型提供技术支持。
python是一种丰富而强大的类似胶水的编程语言,由于其简单、容易上手等原因,在不同领域均有很强的需求。特别在数据分析、机器学习及人工智能等领域,受到人们热烈的追捧。在2018年7月的编程语言排行榜[2]中,python稳居所有编程语言第一名。
worldwide,Jul 2018 compared to a year ago: | ||||
Rank | Change | Language | Share | Trend |
1 | ↑ | Python | 23.59% | +5.5% |
2 | ↓ | Java | 22.40% | -0.5% |
3 | ↑↑ | Javascript | 8.49% | +0.2% |
4 | ↓ | PHP | 7.93% | -1.5% |
5 | ↓ | C# | 7.84% | -0.5% |
6 |
| C/C++ | 6.28% | -0.8% |
7 | ↑ | R | 4.18% | +0.0% |
8 | ↓ | Objective-C | 3.40% | -1.0% |
9 |
| Swift | 2.65% | -0.9% |
10 |
| MATLAB | 2.25% | -0.3% |
图2-1世界范围内编程语言流行度排名图
因运营商移动网络优化领域现如今面临的挑战主要有:
(1)移网网络复杂、多种制式网络共存,存在多个网管平台及数据平台,简单来说就是多而杂,维护困难度高。
(2)网络优化中数据庞大,因平台较多,数据量也逐渐上升,如果通过人工来每天监控及分析相关指标会变的力不从心,且如果对非常细化的指标进行监控并对出现的问题提出解决方案,此项工作就会消耗较多的人力资源。
移动网络优化是追求网络在动态平衡中的最优状态,为达到这种最优状态及应对以上挑战,有的工作数据已经大到excel等无法操作,python此时就脱颖而出。同时现如今用户对网络敏感度越来越高,快速定位用户问题就显得至关重要,而python的自动化及智能化分析就有了较大的优势。
网络爬虫顾名思义就是从浩瀚的网络上爬取你所需要的数据。Python在这方面就是一个很有优势的语言。比如我们日常用到的搜索引擎或搜索工具就可以看作是网络爬虫的升级版本,在搜索框输入你需要查询的关键字后就能输出你想要的结果,该爬虫技术为通用性爬虫,此外还有聚焦型爬虫:主要是聚焦某些特定的数据,以此为基础爬取网页的技术;增量型爬虫:在聚焦型爬虫的基础上,定期需要增加特定内容的爬虫技术;深层爬虫:该爬虫技术与其他技术主要的区别是需要先进行安全验证,验证完成后再进行数据的爬取的技术。由以上可知爬虫的一个通用流程就是:程序调用爬虫模块端后给定URL,后续根据一定规则爬取网页信息,后通过下载指令完成对网页数据的爬取,在通过网页解析器将下载的数据解析成我们看懂的信息,以上就是一个简单的通用型网络爬取流程。图2-2就是简单的通用型爬虫流程。
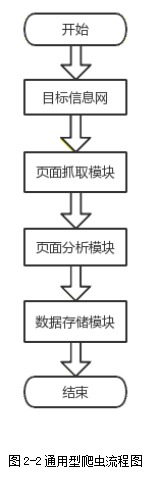
图2-2通用型爬虫流程图
移动网络的更新迭代已经进入了5G的时代,传输速率的增大为数据大量交流铺设了平台,所以现如今已经逐渐进入了大数据的时代,对数据这个宝藏库进行分析与挖掘就有了很大的研究意义,从广义数据分析类型上我们分为狭义数据分析与数据挖掘。
狭义数据分析:主要通过对比、分组、交叉、回归分析等分析手段来对我们爬取收集到的数据进行处理与分析,提取出有价值的数据,帮助我们研究与决策。
数据挖掘:主要是在海量的、无规律的、不完整的、有噪声的、模糊的、随机的数据中通过一系列特定规则如关联规则、分类规则、聚类规则、智能推荐等手段挖掘出数据中我们没有发现的数据价值。
目前主流的数据分析语言有R;Python;MATLAB。图2-3简单进行了比较,可发现在爬虫与数据分析方面,Python有很大的优势。
| R | Python | MATLAB |
语言学习难易程度 | 入门难度低 | 入门难度一般 | 入门难度一般 |
使用场景 | 数据分析,数据挖掘,机器学习,数据可视化等。 | 数据分析,机器学习,矩阵运算,科学数据可视化,数字图像处理,web应用,网络爬虫,系统运维等。 | 矩阵计算,数值分析,科学数据可视化,机器学习,符号计算,数字图像处理,数字信号处理,仿真模拟等。 |
第三方支持 | 拥有大量的Packages,能够调用C,C++,Fortran,Java等其他程序语言。 | 拥有大量的第三方库,能够简便地调用C,C++,Fortran,Java等其他程序语言。 | 拥有大量专业的工具箱,在新版本中加入了对C,C++,Java的支持。 |
流行领域 | 工业界≈学术界 | 工业界>学术界 | 工业界<学术界 |
软件成本 | 开源免费 | 开源免费 | 商业收费 |
图2-3主流数据分析语言排名图
移动网络优化中告警监控自动化分析程序在本文中主要采用python的深层爬虫技术及pandas模块等其他模块来完成数据分析,为移网优化工作人员提供每日网络的告警情况,为优化及其他工作做好准备工作。图3-1展示本次python自动化分析程序结构,方便了解程序过程。
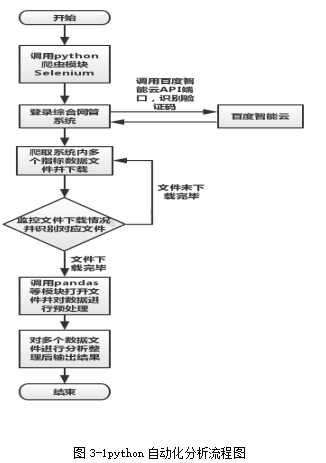
图3-1python自动化分析流程图
因python有很多自带及第三方库,当我们需要的时候,就需要将这些库先引入到程序中才能进行操作。在爬虫程序中我们涉及了selenium,time,os,PIL,requests,request,json,base64这个几个模块,很好的帮助我们进行网络数据的爬取。首先我们需要对浏览器加装webdriver的补丁,由此补丁后才能完成对浏览器的调用。其次就需要将用到的三方库进行引入,下面是本次程序需要引入的模块。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
from PIL import Image
import requests
import urllib.request
import json
import base64
import pandas as pd
import datetime
在引入python自带库与第三方库后,我们需要对浏览器进行配置,来保证浏览器能自动下载并存入我们想要保存的位置。我们以火狐浏览器FireFox来举例,可使用下文程序中的配置来完成。主要对浏览器内下载路径,保存提示框的显示与否,快速自动保存等进行配置,保证我们爬取的数据保存到我们指定的位置。
driver = webdriver.Firefox()
driver = webdriver.FirefoxProfile()
driver.set_preference("browser.download.folderList", 2)
# 0是下载到桌面,1为浏览器默认下载路径,2是下载到指定目录
driver.set_preference("browser.download.dir", r'D:\\gaojing\\')
driver.set_preference("browser.download.manager.showWhenStarting", False)
# false设置为不显示
driver.set_preference("browser.download.forbid_open_with", True)
#不打开保存的提示框
driver.set_preference("browser.altClickSave", True)
#快速保存# 不询问下载路径:后面的参数为要下载页面的content-type的值
driver.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/octet-stream,application/vnd.ms-excel,text/csv,application/zip")
driver = webdriver.Firefox(firefox_profile=driver)
至此,爬虫的准备工作就已经结束,已将将我们需要的浏览器等设置成为我们需要的配置,下面就开始对移动网络数据平台进行爬虫,来爬取我们需要的文件。
在爬虫准备工作完成后,就开始我们的爬虫工作,因移动网络数据平台安全性要求较高,因此该系统存在用户名、密码、验证码的三层验证后才能登录。为完成以上工作,我们采用深层型爬虫技术来爬取数据。下文程序是登录移动网络综合平台的一个爬虫程序。在本次登录过程中,因验证码的存在,需要对验证码进行识别,该自动识别有一定难度,我们通过调用百度智能云API来进行识别,经过多次实践发现百度云识别成功率几乎保持在99.9%以上。识别成功率非常高,很适合我们此次分析的要求,所以我们最后就借用了百度智能云的算法能力。
url = 'http://*.*.*.*/login.jsp'
driver.get(url)
driver.find_element_by_id('username').send_keys('***')
driver.find_element_by_id('password').send_keys('***')
driver.save_screenshot('D:\yanzhengma.png')
security_code_element = driver.find_element_by_xpath('/html/body/form/table/tbody/tr[4]/td[2]/table/tbody/tr[2]/td[4]/img')
left = int(security_code_element.location['x'])
top = int(security_code_element.location['y'])
right = int(security_code_element.location['x'] + 60)
bottom = int(security_code_element.location['y'] + 20)
im = Image.open('D:\\yanzhengma.png')
im = im.crop((left,top,right,bottom))
im.save('D:\\security_code.png')
time.sleep(5)
ak = '*******'
sk = '*******'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=
client_credentials&client_id=%s&client_secret=%s' %(ak,sk)
request = urllib.request.Request(host)
request.add_header('Content-Type','application/json; charset =UTF-8')
response = urllib.request.urlopen(request)
content = response.read()
json_all = json.loads(content)
#调用接口
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/numbers"
# 二进制方式打开图片文件
f = open('D:\\security_code.png','rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = json_all['access_token']
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
ocr = response.json()
try:
for item in ocr['words_result']:
secruity_code = item['words']
print(secruity_code)
except:
print('错误')
driver.find_element_by_id('code').send_keys(secruity_code)
在验证码的自动识别过程中,我们需要先将验证码的图片截取下来,通过对网页的分析,确保我们截取的图片是完整清晰的,后将图片发送到百度智能云接口,因百度智能云有加密过程,需要设定自己的Ak与SK密匙。完成此步操作后,百度云就会将识别后的验证码发送回来,经过解码就是我们验证码图片中的验证码。0
经过安全验证进入到移动网络数据平台后需要进行有关多个数据的表格的爬取,爬取过程中需要对HTML5语言及CSS有所了解,主要通过网页id及xpath路径等对网页元素定位,以此来完成对数据爬取。对于HTML5及CSS语言问题,本文不在赘述。
对爬取的数据进行分析前,需要对数据进行预先处理,因下载的数据文件名称每次都有变化,需要对所在目录进行监控,确保数据下载完成后再对数据进行处理,下面自定义了一个判断文件,对文件下载目录进行监控。
def panduan():
dirnum = 0
filenum = 0
path = 'D:\\gaojing\\'
for lists in os.listdir(path):
sub_path = os.path.join(path, lists)
#print(sub_path)
if os.path.isfile(sub_path):
filenum = filenum+1
elif os.path.isdir(sub_path):
dirnum = dirnum+1
return filenum
当上文程序监控到文件下载完成后,程序就会对文件目录内文件进行遍历查询,查询出所有文件的详细地址情况,通过对文件名的关键字进行筛选匹配后,找到我们每天需要分析的文件。
def finder(pattern, root):
matches = []
dirs = []
for x in os.listdir(root):
nd = os.path.join(root, x)
if os.path.isdir(nd):
dirs.append(nd)
elif os.path.isfile(nd) and pattern in x:
matches.append(nd)
for match in matches:
# print(match)
return match
for dir in dirs:
finder(pattern, root=dir)
对数据预处理进行完成后,通过python的pandas的模块打开我们需要分析的文件,使用drop、contains、loc、fillna、merge、concat、sort等及 datetime等模块对数据进行删除、筛选、vlookup、告警分类,如:驻波、时钟、零话务、RRH故障原因判断、光的衰弱问题等告警进行归类、聚合,同时又对告警时间等进行判断,频闪或者自动恢复,或者仍未恢复,由此来保证数据的一体性,可关联性,高准确性、高可靠性。下面是对一小段数据进行分析的编程设计。
df6 = pd.read_excel(lishihuoyue,sheet_name ='4G',header =3)
df6 = df6.drop(['Unnamed: 0'],axis=1)
df6 = df6[df6['地市'].str.contains('临河')]
df6 = df6[df6['IS_PETITION'].str.contains('是')]
if df6['ALARM_TEXT'].str.contains('clock') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('clock'),'告警原因']='时钟丢失'
#筛选为时钟的告警,并标注出来
if df6['ALARM_TEXT'].str.contains('VSWR') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('VSWR'),'告警原因']='驻波'
if df6['ALARM_TEXT'].str.contains('optical') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('optical'),'告警原因']='光或电导致小区掉'
if df6['ALARM_TEXT'].str.contains('baseband') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('baseband'),'告警原因']='基带板故障'
if df6['ALARM_TEXT'].str.contains('RF Module') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('RF Module'),'告警原因']='射频模块故障'
if df6['ALARM_TEXT'].str.contains('Fan failure') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('Fan failure'),'告警原因'] ='风扇告警'
if df6['ALARM_TEXT'].str.contains('Cell disabled due to unknown problem') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('Cell disabled due to unknown problem'),'告警原因'] ='小区掉因未知原因'
if df6['ALARM_TEXT'].str.contains('Cell power failure') is None:
df6
else:
df6.loc[df6['ALARM_TEXT'].str.contains('Cell power failure'),'告警原因'] ='小区电力故障'
df6 = df6.drop(['告警唯一标识','网元类型','网元标识','地市','厂商','告警级别','告警原始原因','告警号','CLEAR_TEXT','START_TIME','NET_TYPE','IS_PETITION','COMMENTS','基站状态','LAC','CELL_ID'],axis=1)
df6 = df6.sort_values(['告警结束时间'],ascending=False)#倒序排序
df6 = df6.loc[(df6['告警结束时间']>today)]#筛选到通报时还没有解决的告警
df6 = df6.merge(gongcan4G,how='left',on='网元名称')
df6['旗县'].fillna(df6['区域'],inplace=True)
df6['基站中文名'].fillna(df6['小区名称'],inplace=True)
df6 = df6.drop(['区域','小区名称'],axis=1)
dfs =pd.concat([df5,df6],sort=False)
dfs = dfs.drop_duplicates(['网元名称'])
通过数据分析后,对最后汇总的2G、3G、4G、5G数据进行旗县级别的分类,每日分发到各旗县及网管进行问题点的处理,保证网络健康度、保证用户使用感知。图3-2列出了移动网络自动化分析的告警监控的部分结果,地市公司以此结果为依据处理影响用户感知的问题点,此项工作原来由网优人员每天处理时大概需要30分钟,现在实现自动化后,每日仅需2分钟就可以搞定。极大了提升了工作效率。
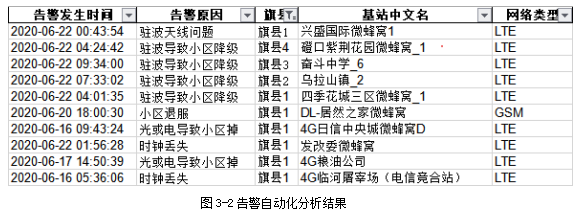
图3-2告警自动化分析结果
本次通过python在百度地图上对某地市住宅小区进行了爬取,主要通过百度地图标签为住宅小区的地点进行爬取,同时利用网络围栏对住宅小区进行划分,后以此为依据对住宅小区进行移动网络深度覆盖等分析,为住宅小区用户提供体验感知更为良好的网络,同时发现住宅小区覆盖盲点,公司以此进行精准投资。此次网络爬虫共爬取到了502个住宅小区。各住宅小区在旗县分布情况,如图4-1的表格。住宅小区旗县分布情况与城市大小向吻合,爬取数据检验准确。
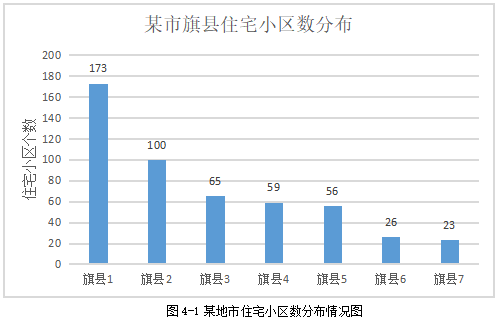
图4-1某地市住宅小区数分布情况图
经过分析,该地市运营商在住宅小区内总体网络情况平稳,LTE无线接通率98%,日均网络资源利用率43%,CQI大等7的比例为93%,平均CQI为11.23,用户感知速率为25.77Mbps,但是在网络忙时,住宅小区网络负荷较大,平均无线资源利用率为116.73%,需加大住宅小区网络容量,为用户提供良好体验感知。

图4-2某地市住宅小区平均RSRP图
从图4-2可知,旗县住宅小区覆盖情况排名中,旗县6为-89.7dBm、旗县7为-91.13dBm、旗县1为-91.23dBm,以上几个旗县中排名较好,其他旗县覆盖不理想,覆盖不理想后会对VOLTE通话,上网感知等都会有影响。针对覆盖较差的住宅小区已提交建设进行基站建设等相关措施,争取使旗县住宅小区整体覆盖达到提升。
本次通过对全部在网络用户进行数据爬取,通过对比基站覆盖范围来划分覆盖住宅小区的基站,然后通过住宅小区占该基站覆盖的面积为比值即:,其中a 为概率,b为住宅小区面积,c为基站覆盖面积,
为基站小区在住宅小区内覆盖的面积,以概率a为系数计算住宅小区内用户数。即
,其中d为住宅小区用户,k为基站小区下用户数。通过以上的方法对住宅小区用户数进行统计。
从图4-3可知,本次地市共选取502个住宅小区,日均用户总数达到了123858人,其中旗县1为59092人,旗县2为21416人,旗县3为18126人,旗县4为11654人,旗县5为7174人,旗县6为3406人,旗县7为2990人。按照区县每个住宅小区平均人数排名为,旗县1为(342人),旗县3(279人),旗县2(214人),旗县4(198人),旗县6(131人),旗县7(130人),旗县5(128人)。根据全市住宅小区日均规模来看,我们发现住宅小区内联通用户占比并不高,在携号转网的情况下,用户其实更无顾虑的来选择运营商,这既是机遇也是挑战,找到我们网络覆盖优势小区来进行营销,实现用户在住宅小区市场占有率,同时对于覆盖较差住宅小区,及时补齐短板,让移动数据网络在住宅小区中成为精品网络。

图4-3住宅小区人数爬取
通过本次基于python的住宅小区数据分析,总共从下面的3张图进行分析。具体分析如下:
图4-4中主要反映了区县住宅小区平均移网覆盖情况(信号强度),平均每个住宅小区日均人数,用户感知速率的关系,可以看出在RSRP为(-89dBm,-94dBm)间,用户感知速率与覆盖情况关联不大,与在网用户数关联关系更大,用户越多,用户感知速率越低。
图4-5反映了区县网络忙时资源利用率与日均网络资源利用率的情况,分析数据发现,如果日均网络资源利用率过了60%,那么忙时网络资源利用率一般就过了100%。旗县3,旗县1,旗县4网络资源利用率较高,日均资源利用率超过了70%,通过与图4-4纵向比较,发现该区域用户感知速率排名后三,所以需要对上述区域进行网络扩容,由此才能带来用户感知速率提升。


分析图4-6发现,住宅小区区县日均使用流量与区县用户人数成正比,排名相同。
但是我们将维度换成区县每个住宅小区日均流量使用量排名后发现,旗县3、旗县4、旗县2排名靠前,说明这些旗县小区网络投资回报率较高,然后我们与区县每个住宅小区人数做对比后发现,只有旗县1波动较大,其他排名基本没有变化,流量与人数基本成正比,旗县1区住宅小区平均用户数第一,但旗县1住宅小区流量使用量仅排名第4,可发现旗县1平均到每个小区,每个小区平均价值并不高,还有提升的空间,建议市场积极对旗县1住宅小区加大营销,提高住宅小区价值量。
我们又分析了各个区县每个小区人均流量使用情况,发现旗县5、旗县6、旗县4排名靠前,旗县7、旗县3、旗县1排名靠后。造成这样的原因可能有以下几种:
(1)用户上网习惯的不同造成此种结果。可能旗县5用户更爱用LTE网络上网。
(2)融合套餐(手机+宽带)发展不均衡的影响。
(3)用户使用LTE网络感知速率好,其中旗县5用户感知速率最高,人均也使用最高。
综上所述,在大数据与人工智能时代,移动网络优化的自动化分析将是每个移动网络优化人员必备的技能,将复杂庞大的网络维护做成简单的网络维护是我们一直努力的方向,此次自动化分析将原来网优人员每天30分钟的工作量在2分钟内完成,极大的提升了工作效率,节省了公司的人力资源,同时通过大数据分析,寻找移动网络问题点,发现网络薄弱环节,助力市场发展及精准营销有很大的辅助作用。最后希望网络优化在python的加持下朝着自动化与智能化方向发展。
参考文献:
[1] 第44次中国互联网络发展状况统计报告.工信部
[2]张俊红.python数据分析.北京.电子工业出版社,2019.2